




论文地址:Poly-encoders: Transformer Architectures and Pre-training Strategies for Fast and Accurate Multi-sentence Scoring,ICLR 2020
前两回链接:
在前两回中,我们讲了Yahoo和脸书的搜索架构和方法。目前大家对搜索中引入ANN的框架应该比较清楚了,后面就开始讲如何进行策略迭代了。在策略迭代中,我们主要基于数据和模型结构进行改进。在本文,我们将介绍一种基于模型结构进行的改进:Poly-encoders。
总的来说,这篇文章在我看来主要有两个贡献:
下面我们开始介绍这两个贡献的细节。在介绍新的模型结构poly-encoder之前,我会先把经典的模型结构bi-encoder和cross-encoder也进行介绍,以便于对比。
下面我们将介绍召回中常用的Bi-encoder、排序中常用的Cross-encoder以及本文提出来的新结构Poly-encoder。
Bi-encoder是召回中常用的模型结构。为什么这个模型结构在召回中常用?我们在讲完模型结构的细节后来回答这个问题。首先,我们给出模型结构图示。
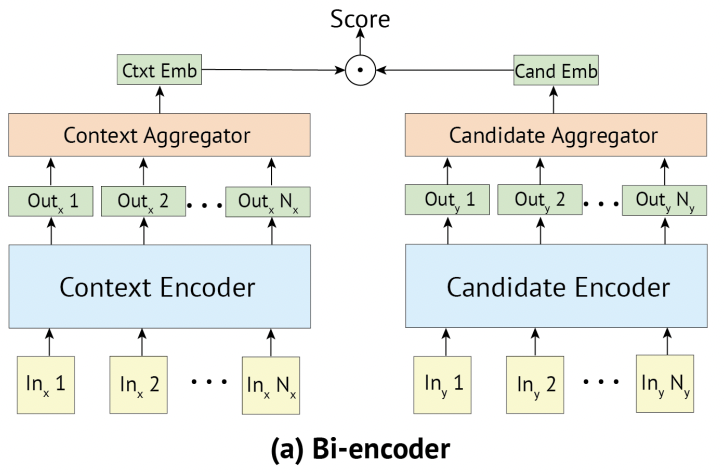
在上图中,左边的输入(ln 1, ..., ln N)可以看作是query中的字/词,右边的输入可以看作是URL的title的字/词。中间的context encoder通常使用的Transformer堆起来的BERT模型。Context Aggregator通常是取(Out1, ..., Out N)中的第一个向量,即CLS对应的向量。这部分如果没有听懂的话,说明对于BERT模型的掌握还不够,需要进行回顾。最后输出的score是Ctxt Emb和Cand Emb两个向量的内积。
现在我们回答一下最开始的问题:为什么这个模型结构在召回中常用?首先我们看到这个模型结构对于Query和URL的处理是分开的,只有在最后计算score的时候才有交互。因此,在召回中,通常在离线计算时,就将URL的向量表示Cand Emb计算好并保存在index库中 (具体可以参考第二回的脸书架构)。在在线计算Query-URL打分时,只需要计算Query的向量表示Ctxt Emb和QU打分Score就好。另外,分开计算Query和URL的向量表示的时间复杂度比合并计算Query和URL的向量表示的时间复杂度要低很多,从而可以更快地从海量数据中选出相关结果。
Cross-encoder通常用于排序阶段,因为排序阶段的数据量少,对效果要求高。cross-encoder的效果好的主要原型是因为Query-URL之间有交互 (见下图),但是cross-encoder的时间复杂度高出bi-encoder很多,所以这个模型只能用于排序阶段。下面我们给出cross-encoder的图示:

在上图中,我们可以知道输入是将Query和URL进行拼接后再进行输入。Encoder仍然是BERT模型。Aggregator通常是取第一个向量,然后输出Cand Emb。最后,dim reduction是一个全连接层将数据变成一个一维的打分。
Poly-encoder主要是希望在bi-encoder (速度) 和cross-encoder (效果) 之间找一个平衡点。下面我们给出poly-encoder的图示,并进行细致地讲解。
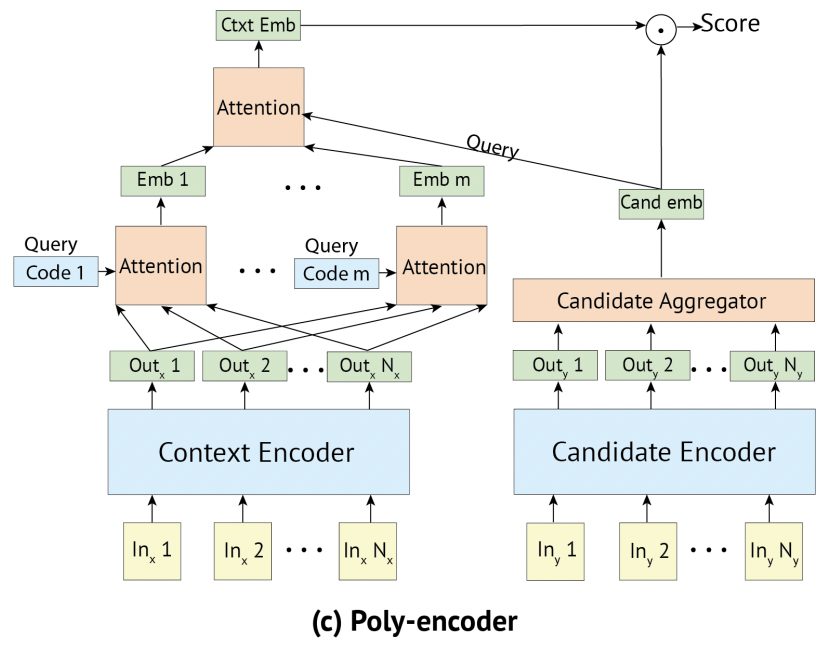
从上图可以看出,Query侧的处理和Context侧的处理是完全不一样的。在Query侧中,引入了code向量。这里我们放慢脚步,从公式和向量维度一点点地剖析这个结构。由于Doc侧的处理是没有变化的,所以我们只介绍query侧的细节。
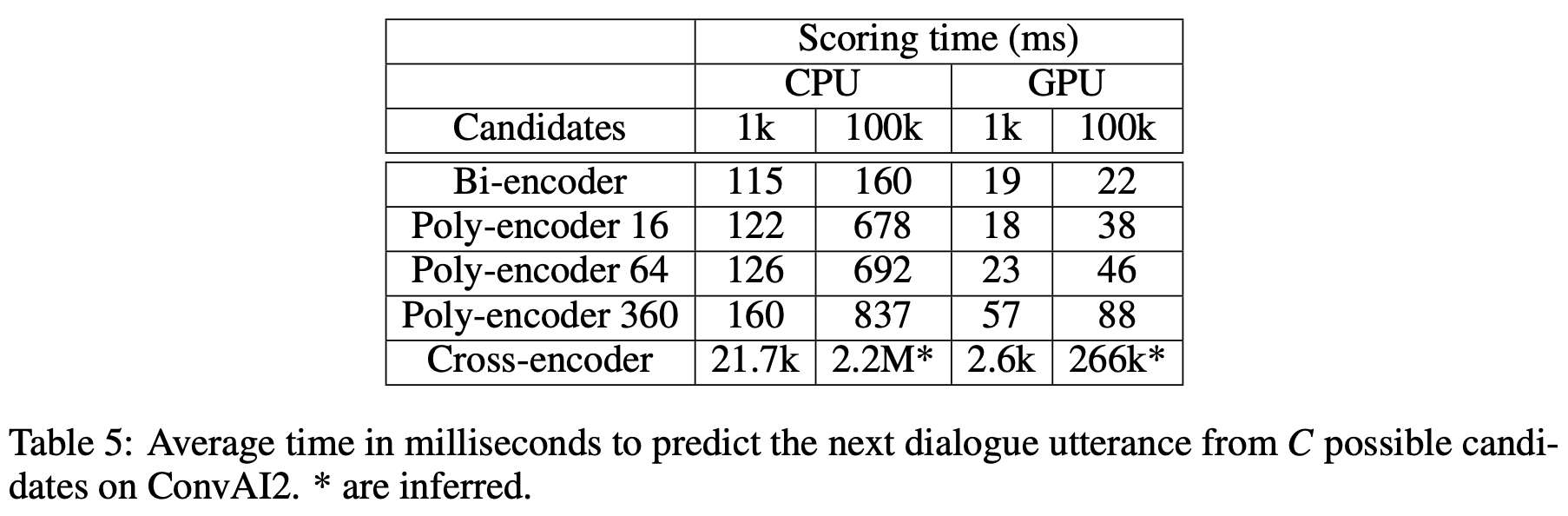
时间消耗对比:
效果对比:
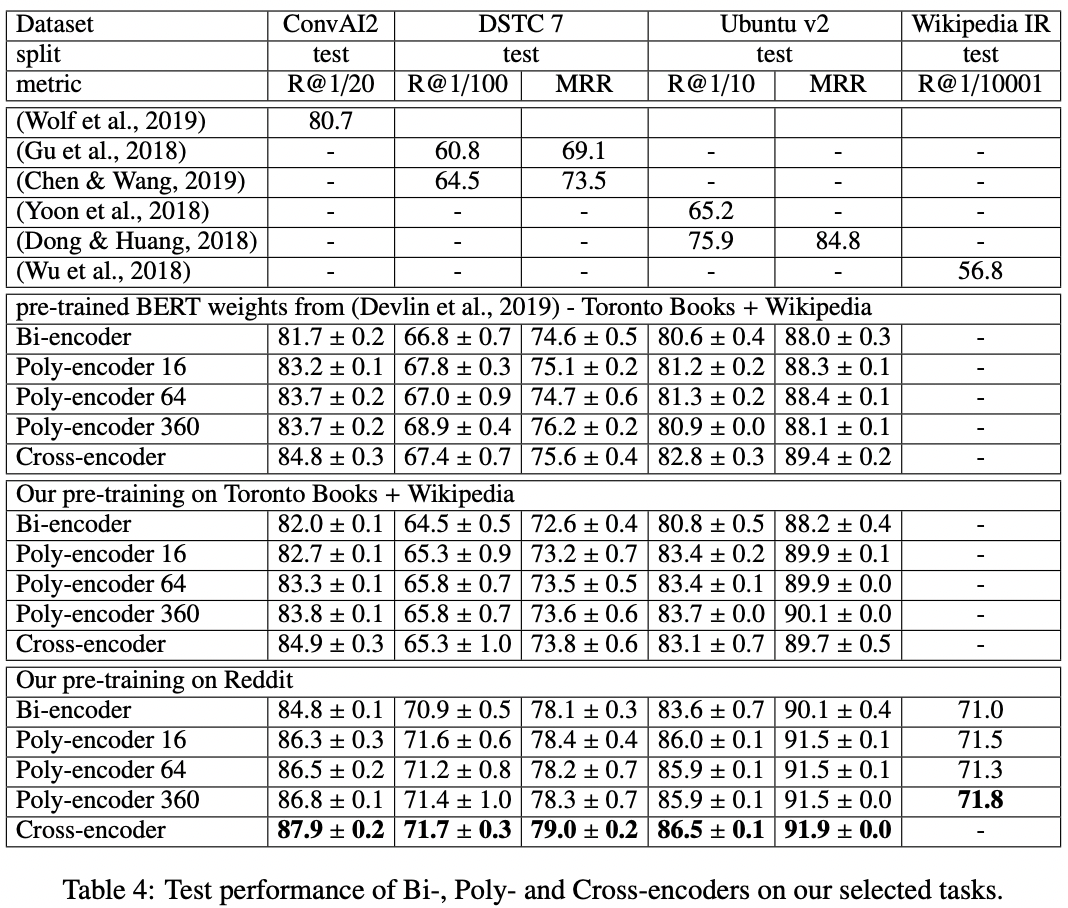
这篇论文不仅仅复现了BERT论文的效果,还探索了使用对话任务相关的语料进行模型预训练对于对话任务的效果是否有帮助。论文使用Reddit数据进行预训练,而且在MLM和NSP任务的基础上,新增了next utterance prediction任务,这个任务类似于NSP任务,只是将NSP任务中的next sentence换成了对话任务的一个回答。换句话说,NSP任务的输入是(上句,下句),而next utterance prediction任务的输入是(对话中的上句,对话中的下句)。在下图中,我们给出实验效果对比。
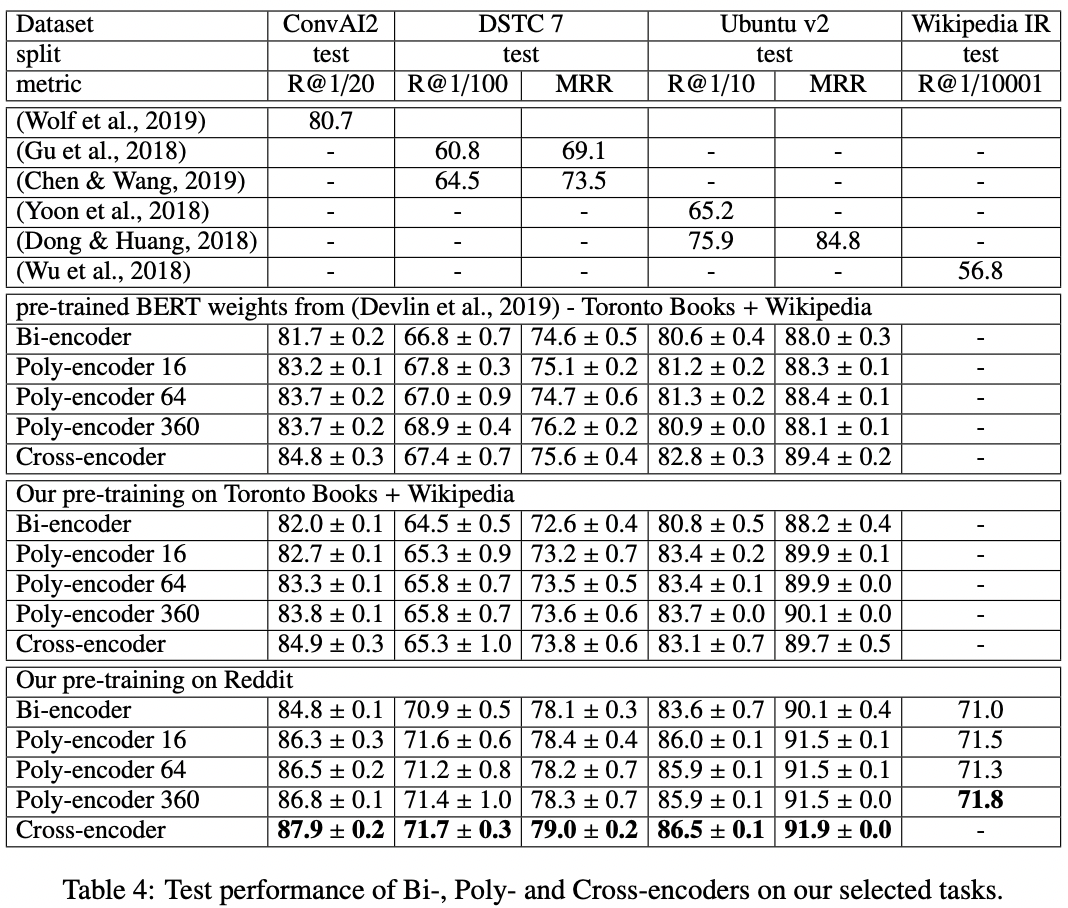
可以看出,使用任务相关语料进行预训练,效果上可以提升2-6个百分点。
最后,推荐大家关注一下我的公众号:深度学习与NLP专栏。








